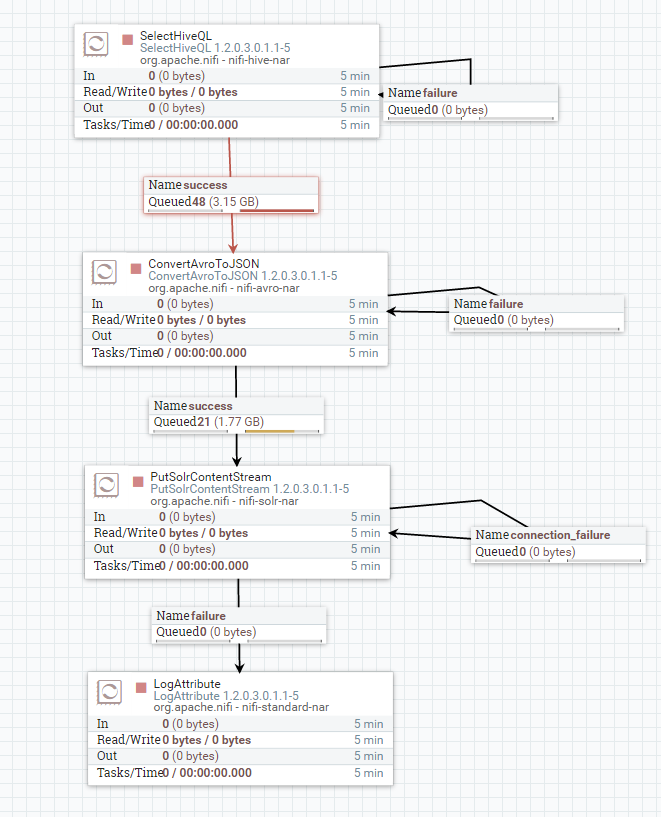
本文主要介绍从Hive中获取数据,将数据写到solr中,ConvertAvroToJSON 注意一下avro schema 如下:
{ "namespace": "", "type": "record", "name": "TEST_DATA1", "fields": [ {"name": "ENAME", "type": "string"} ] }
solr 分为两种模式,standard和cloud两种
standard :solr type 选择standard
solr location 配置 http://ip:port/solr/collectionName
Collection 不配置
cloud : solr type 选择cloud
solr location 配置成 Zookeeper地址 例:
packone11:2181,packone12:2181,packone13:2181/infra-solr
collection 配置